
相信很多运营及编辑的同学在工作中都会遇到各种文本处理的问题,如这篇文章放哪里?这类内容在什么频道?有过在大型网站工作过的同学肯定会深受其害,很多也是导致各种‘忙成狗’的原因之一,去年腾讯的机器编辑新闻可能大家都不陌生,大家回想以后是不是不需要编辑啦之类的问题,其实一些东西确实是可以通过技术解决的,今天就发现一个通过技术实现文本自动分类的例子
首先几个名字
1自然语言处理
2机器学习
3词向量
感兴趣的同学可以去网上查查相关的名词了解下,对经常与文字打交道的童鞋来说,了解这些技术东西还是非常有必要的。
进入主题
使用的工具
1 Python
2 textgrocery库
不会技术的同学先不要慌,我相信很多同学大学都有学过 c语言,没错 只要您了解基本的编程知识,了解下Python这门语言就够用啦!
还是来讲讲Python的安装吧 这里不给大家详细讲了,直接上一个window系统下安装Python的教程和安装软件一样的简单。
http://jingyan.baidu.com/article/7908e85c78c743af491ad261.html
现在的Python版本都集成的下载(pip install)功能
安装好 Python后 ,打开电脑输入 CMD 按enter打开cmd窗口
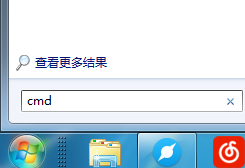
输入 pip install tgrocery
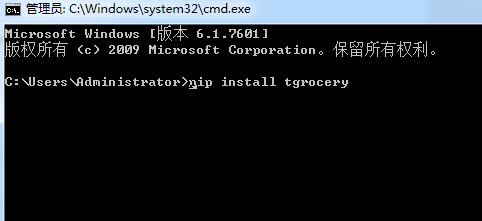
到这里你需要的工具都准备完成了
给大家上一段 grocery官方文档的地址
http://textgrocery.readthedocs.io/zh/latest/quick-start.html
重点说下原理
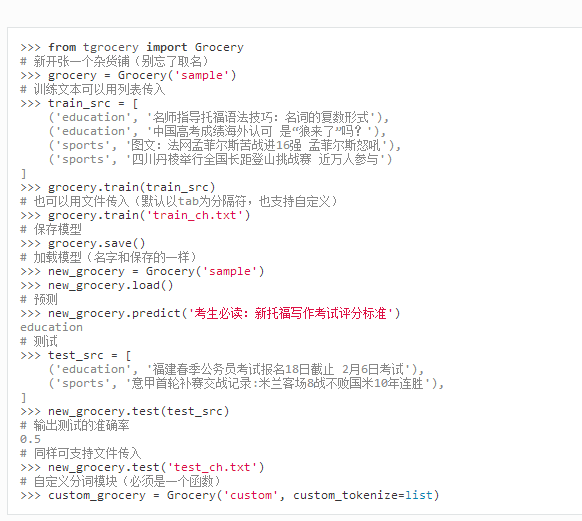
看懂了吗?没错就这么简单
可以预见这段代码的执行后的结果
当然这只是对文章的标题进行分析,
结果肯定不准确,如果想对文章内容进行分析本进行归类的话,其实也不是特别麻烦
现在主流的网站包括今日头条、腾讯、等等都有自己的一套文本分析系统。既没有想象中的那么复杂,当然也没有想象中的那么简单。无非就是两个规程,
1分析文章的内容,
2对1分析出来的结果进行对比匹配,
包括什么栏目啊,相似文章,文章关键词 等等都可以通过这两步搞定。
有空可以再教大家怎么利用技术批量找到大量文章的关键词!

